
I'm Tetsuo Koyama. Handle of kote2.
Freelance Web Designer
Works
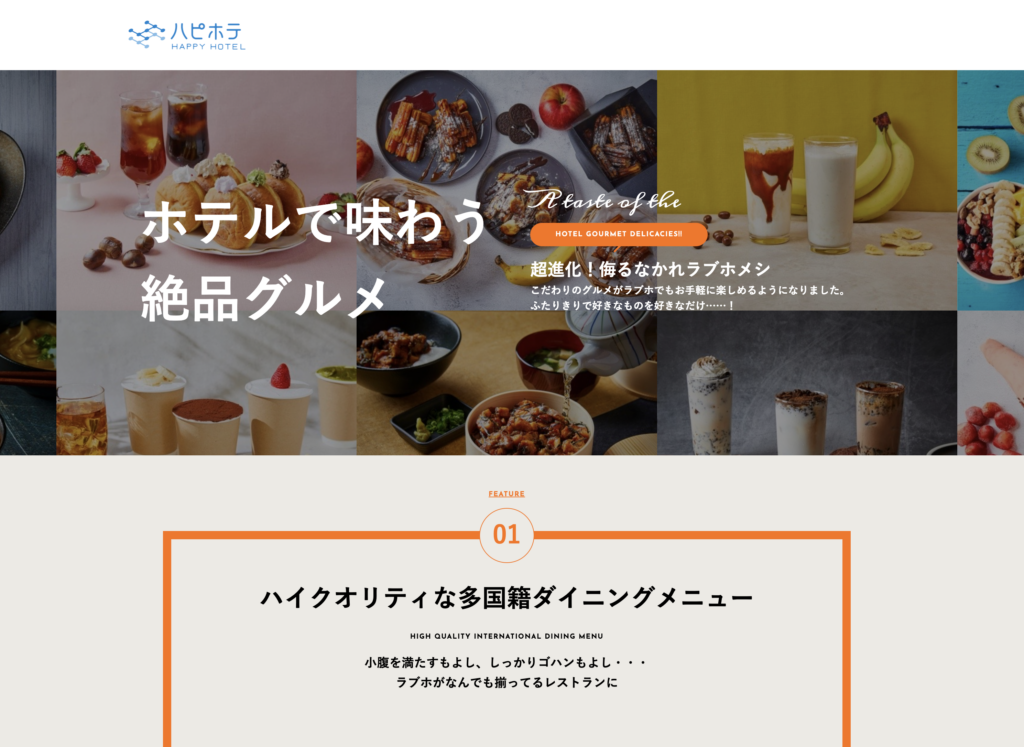


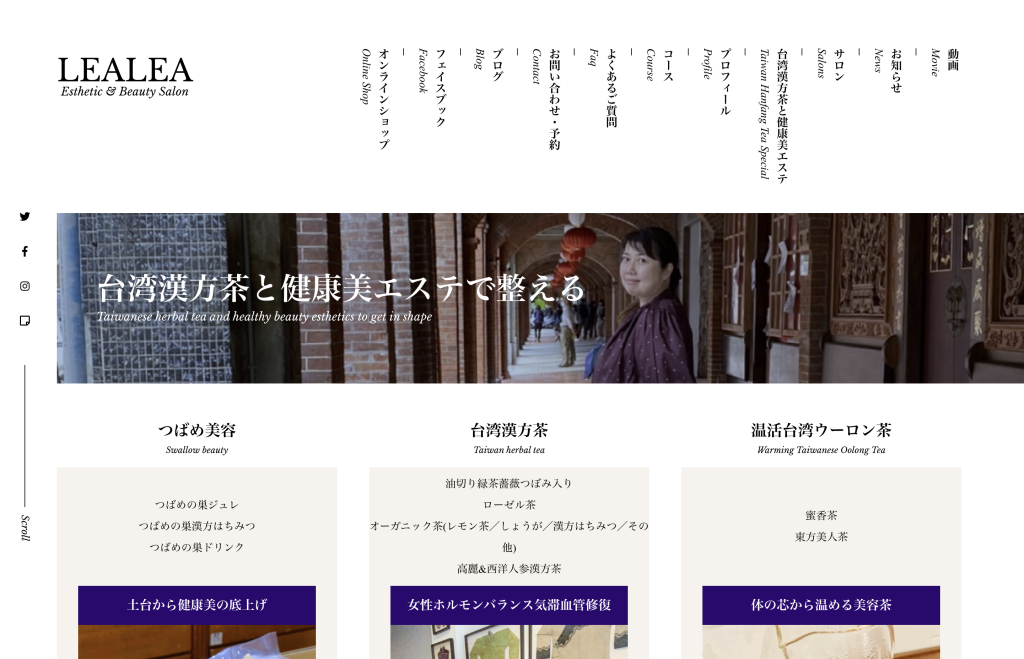
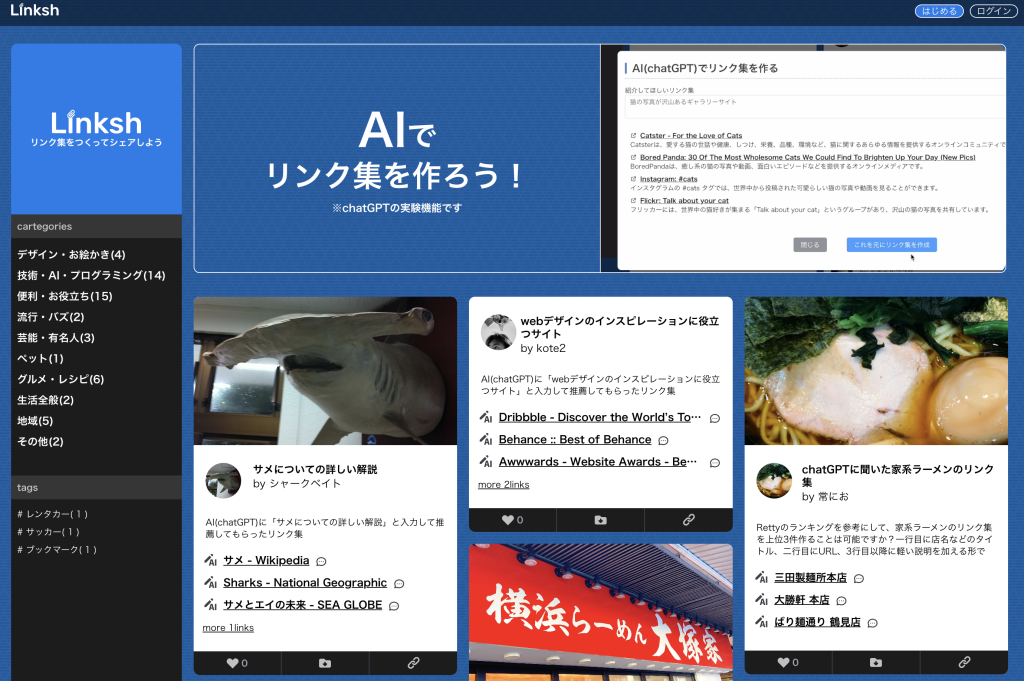
リンク集作成サービスLinkshにChatGPTリンク作成機能追加
Added ChatGPT link creation function to Linksh, a link collection creation
- Personal Development
コーポレートサイト構築と検索システム開発
Corporate website construction and search system development
- Cording
- Development

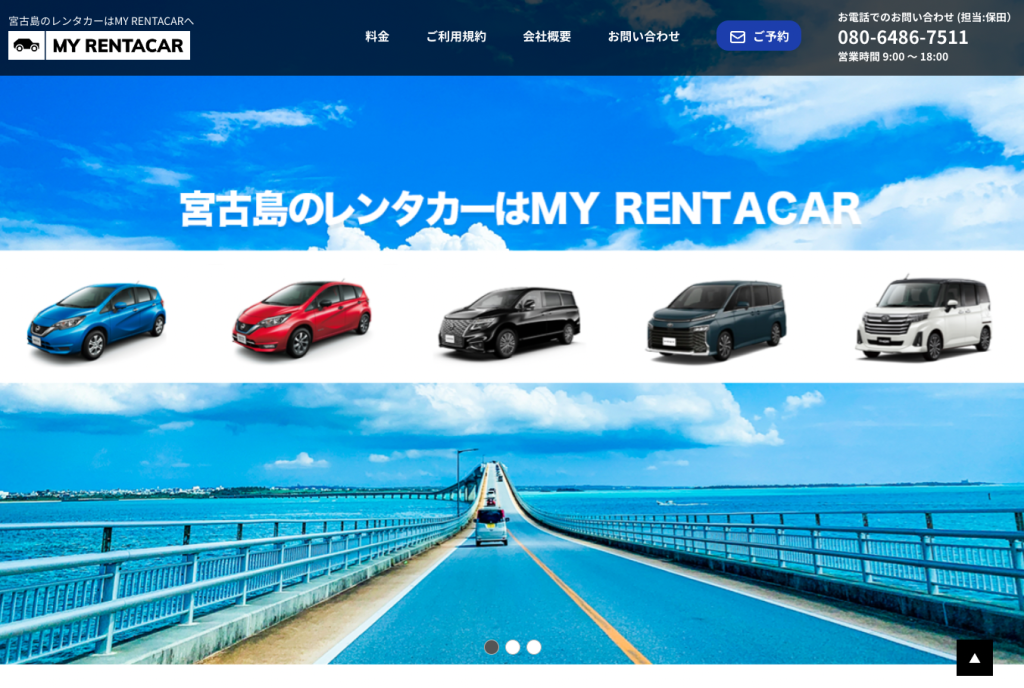
YouTubeチャンネル紹介のLP
- Development
- Personal Development
- Webdesign


kote2.tokyo(このサイト)をNext.jsのISR対応で爆速化
kote2.tokyo (this site) is now blazing fast with Next.js ISR support
- Personal Development
