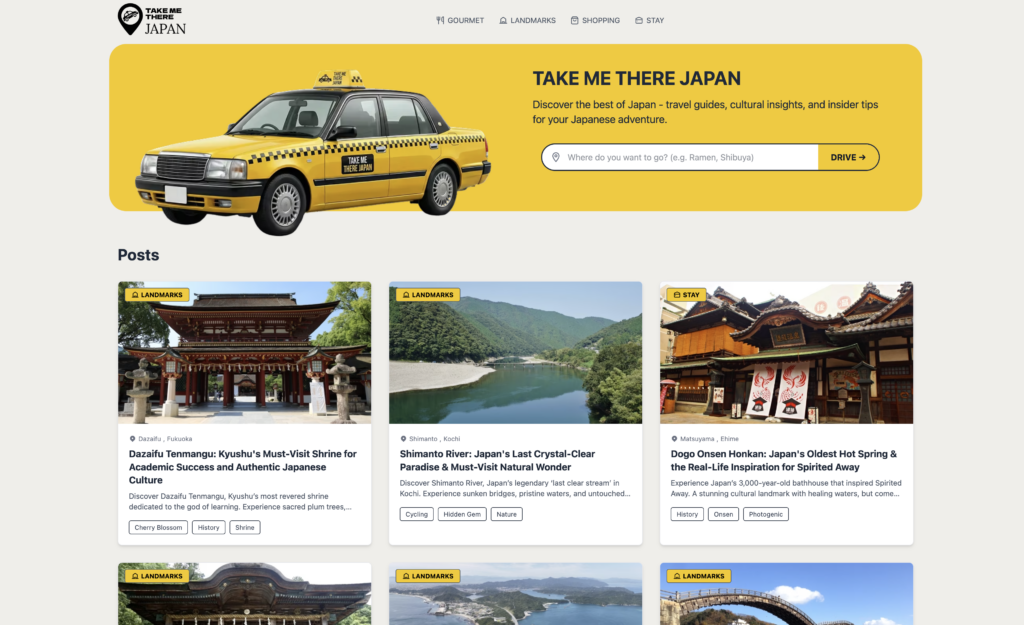
インバウンド訪日外国人向けサイト
AI-powered inbound tourism website built with Astro, Headless WordPress, and Cloudflare.
- Personal Development
AI-powered inbound tourism website built with Astro, Headless WordPress, and Cloudflare.



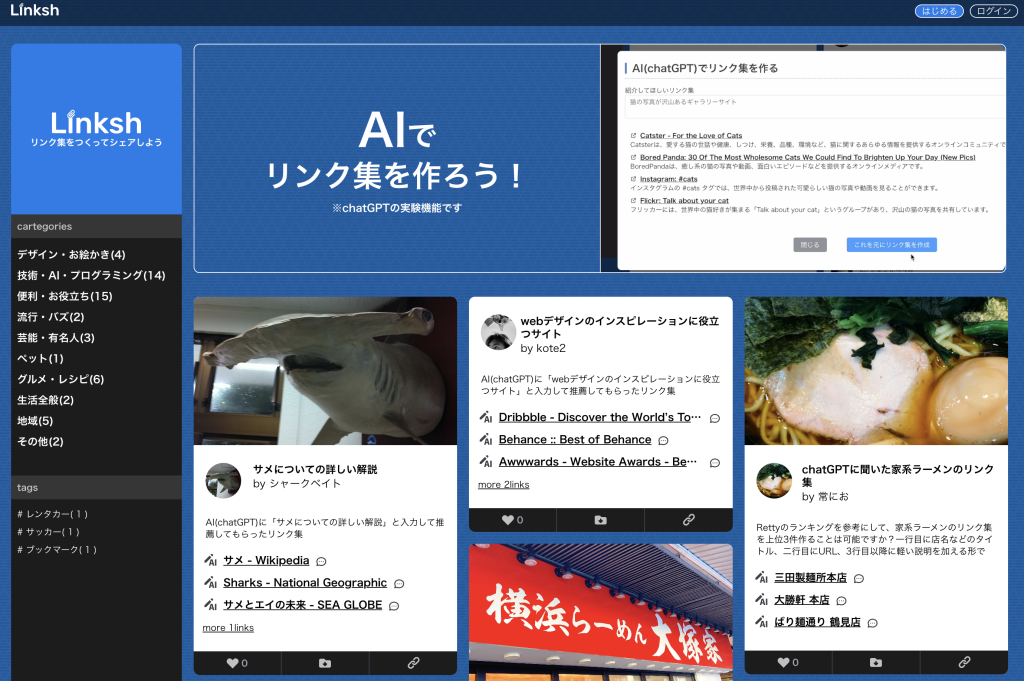
Added ChatGPT link creation function to Linksh, a link collection creation
Corporate website construction and search system development



kote2.tokyo (this site) is now blazing fast with Next.js ISR support
