Blog
- kote2.tokyo
- >
- Blog
- >
- wikipediaから一部データを拝借
wikipediaから一部データを拝借
- Update2016-08-25
- Category
- Internet
- Other--
pandasを使ってwikipediaからデータを一部拝借してみます。
今回は例としてこちらの都道府県の一覧を抜き出すのをやってみます。なお、都道府県リストはページ中程にあるようです。
https://ja.wikipedia.org/wiki/%E9%83%BD%E9%81%93%E5%BA%9C%E7%9C%8C
なお、今回参考にしたのは海外サイトで英語を抜き出したのですが、日本語を抜き出すときはいろいろ言われるので必要であれば以下をpipインスト−ルしておきます。
pip install html5lib pip install --upgrade html5lib==1.0b8 pip install -lxml
公式ドキュメントはこちら
http://pandas.pydata.org/pandas-docs/stable/io.html
まずpandasをインポートします。
import pandas as pd
read_htmlで抜き出して、変数に格納します。
japan_prefectures = pd.read_html('https://ja.wikipedia.org/wiki/%E9%83%BD%E9%81%93%E5%BA%9C%E7%9C%8C')
中身はどうなってるんでしょう?一旦printしてみます。
print(japan_prefectures)

上記のように、配列で渡されるようです。では配列を指定して今度は書き出してみます。つまりデータフレームを作ります。
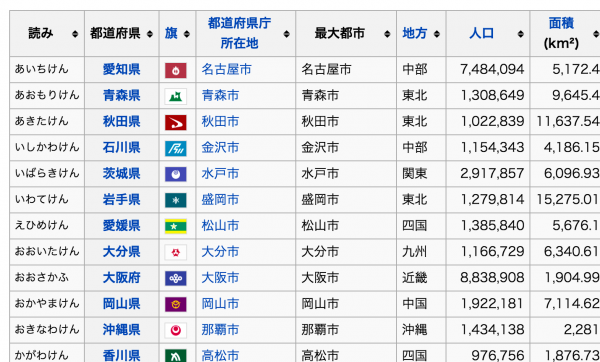
print(japan_prefectures[3])

上記のようにデータフレームが作成されます。
今度はデータフレームの中の都道府県だけを抜き出します。
print(japan_prefectures[3][1]) 0 都道府県 1 愛知県 2 青森県 3 秋田県 4 石川県 5 茨城県 6 岩手県 7 愛媛県 ・ ・ ・
ちゃんと都道府県が抜き出されました。
次はインデックス番号も取り除いて純粋な都道府県のみを抜き出します。for inを使います。
for jpp in japan_prefectures[3][1][1:]:
print(str(jpp))
愛知県
青森県
秋田県
石川県
茨城県
岩手県
・
・
・
無事抜き出せました。ここから先は抜き出したデータをどう加工するかで変化するのでこれくらいにしておきますが、最後にここまで加工したものをcsvで保存したいと思います。
japan_prefectures[3][1][1:].to_csv('japan_prefectures.csv',encoding='SHIFT-JIS')
恐ろしく簡単に書き出せます。
いじょ!