- kote2.tokyo
- >
- Blog
- >
- pythonとパンダちゃんで重回帰分析
pythonとパンダちゃんで重回帰分析
- Update2016-08-30
- Category
- Internet
- Other--
こんばんわ、kote2です。
pythonで重回帰分析をやる方法について調べてわかったのでメモします。回帰分析はあったんですが重回帰分析はほとんど載ってなかったので。。あと重回帰分析について自分は統計学初心者で説明できるほどよくわかってないのでこちらをご参考ください・・。
http://xica.net/sxuwvhyx/
とは言え、重回帰分析って例えばどんなことに使えるのか?
これを考えるのが重要ですね。イメージしやすいし。
例えばあなたはあるソシャゲー会社のマーケティング担当で、WEB広告とCMや雑誌広告の出稿を主な業務としています。さて、WEB広告はお金をかけるだけゲームが売れるのはわかっていますがカバレッジの大きさに限界があり従来メディアへの出稿を余儀なくされています。ただCMや雑誌等は綿密な統計分析ができていません。以前まで行っていた施策のデータ(広告費と売上)がありますが、今回CMと雑誌について最適な予算配分をしたいと考えています。
WEBの担当者であればWEBの広告もAとBというメディアでどのような予算配分が一番効率がいいか考えることがあります。
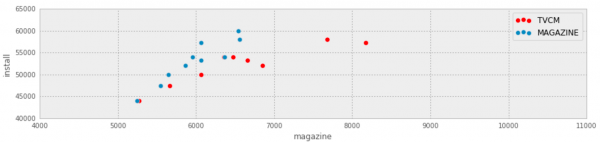
今回は以下みたいなデータフレームを使用しました。
tvcm magazine install month 2015-01-01 6358 5955 53948 2015-02-01 8176 6069 57300 2015-03-01 6853 5862 52057 2015-04-01 5271 5247 44044 2015-05-01 6473 6365 54063 2015-06-01 7682 6555 58097 2015-07-01 5666 5546 47407 2015-08-01 6659 6066 53333 2015-09-01 6066 5646 49918 2015-10-01 10090 6545 59963
まず、実際お金をかければかけるほど新規インストール数って上がるのか?可視化するため散布図を作ってみます。
%matplotlib inline #jupyter用
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#以下はおまじない
pd.set_option('display.mpl_style', 'default')
plt.rcParams['figure.figsize'] = (15, 3)
plt.rcParams['font.family'] = 'sans-serif'
CSVデータを読み込みます。
ad_data = pd.read_csv('ad_result.csv', index_col=0, parse_dates=True)
ad_data
tvcm magazine install
month
2015-01-01 6358 5955 53948
2015-02-01 8176 6069 57300
2015-03-01 6853 5862 52057
2015-04-01 5271 5247 44044
2015-05-01 6473 6365 54063
2015-06-01 7682 6555 58097
2015-07-01 5666 5546 47407
2015-08-01 6659 6066 53333
2015-09-01 6066 5646 49918
2015-10-01 10090 6545 59963
そして散布図をプロットします。
ax = ad_data.plot(kind='scatter', x='tvcm', y='install',color='RED', label='TVCM',s=50); ad_data.plot(kind='scatter', x='magazine', y='install', label='MAGAZINE',ax=ax,s=50);
TVCMは多少バラつきがありますがどちらも右肩上がりに直線を引けそうですね。
直線を引くとこのような感じになります。

で、ここから重回帰分析をしてみます。
公式は
新規インストール数 = (β1✕TVCM広告費 + β2✕雑誌広告費) + α
αとβを重回帰分析で明らかにしてみます。とは言っても簡単。
model_ols = pd.ols(y=ad_data['install'], x=ad_data.drop(['install'], axis=1)) print(model_ols) -------------------------Summary of Regression Analysis------------------------- Formula: Y ~+ + Number of Observations: 10 Number of Degrees of Freedom: 3 R-squared: 0.9379 Adj R-squared: 0.9202 Rmse: 1387.3685 F-stat (2, 7): 52.8620, p-value: 0.0001 Degrees of Freedom: model 2, resid 7 -----------------------Summary of Estimated Coefficients------------------------ Variable Coef Std Err t-stat p-value CI 2.5% CI 97.5% -------------------------------------------------------------------------------- tvcm 1.3609 0.5174 2.63 0.0339 0.3468 2.3751 magazine 7.2498 1.6926 4.28 0.0036 3.9322 10.5674 intercept 188.1743 7719.1308 0.02 0.9812 -14941.3222 15317.6707 ---------------------------------End of Summary---------------------------------
はい、出ました。この部分。
tvcm 1.3609
magazine 7.2498
intercept 188.1743
何もやらなければ188インストールで、広告を使えば費用×上記の係数でインストール数が予測できます。
じゃあ、今回は6万人獲得したいということで
60279 = 1.361✕4200万円 + 7.250✕7500万円 + 188.174
ってな感じで計算できちゃうのでした。上記の広告費の数字はエクセルで計算式作ってしまえば調整が楽ですよ。
いじょ!